Intuition
Forward Marginal Effects (FMEs) are probably the most intuitive way
to interpret feature effects in supervised ML models. Remember how we
interpret the beta coefficient of a numerical feature in a linear
regression model
:
If
increases by one unit, the predicted target variable
increases by
.
FMEs make use of this instinct and apply it straightforwardly to any
model.
In short, FMEs are the answer to the following question:
What is the change in the predicted target variable if we
change the value of the feature by
units?
A few examples: What is the change in predicted blood pressure if a patients’ weight increases by = 1 kg? What is the change in predicted life satisfaction if a person’s monthly income increases by = 1,000 US dollars? Per default, will be 1. However, can be chosen to match the desired scale of interpretation.
Compute Effects
The big advantage of FMEs is that they are very simple. The FME is
defined observation-wise, i.e., it is computed separately for each
observation in the data. Often, we are more interested in estimating a
global effect, so we do the following:
1. Compute the FME for each observation in the
data
2. Compute the Average Marginal Effect (AME)
Numerical Features
Categorical Features
Equivalent to the step size
of a numerical feature, we select the category of interest
for a categorical feature
.
For a given observation
and category
,
the FME is:
where we simply change the categorical feature to , leave all other features unchanged, and compare the predicted value of this changed observation to the predicted value of the unchanged observation. Obviously, we can only compute this for observations where the original category is not the category of interest . See here for an example.
Average Marginal Effects (AME)
The AME is the mean of every observation’s FME as a global estimate
for the feature effect:
Therefore, the AME is the expected difference in the predicted target
variable if the feature
is changed by
units. For
= 1, this corresponds to the way we interpret the coefficient
of a linear regression model. However, be careful: the choice of
can have a strong effect on the estimated FMEs and AME for
non-linear prediction functions, auch as random forests
or gradient-boosted trees.
Why we need FMEs
Marginal effects (ME) are already a widely used concept to interpret
statistical models. However, we believe they are ill-suited to
interpret feature effects in most ML models. Here, we explain why you
should abandon MEs in favor of FMEs:
In most implementations (e.g., Leeper’s margins package), MEs are
computed as numerical approximation of the partial derivative of the
prediction function w.r.t. the feature
.
In other words, they compute a finite difference quotient, similar to
this:
$\textrm{dME}_{\mathbf{x}^{(i)}, \, j} =
\cfrac{\widehat{f}(x_{1}^{(i)}, \, \ldots,\, x_{j}^{(i)}+h,\, \ldots, \,
x_{p}^{(i)})-\widehat{f}(\mathbf{x}^{(i)})}{h}$
where typically is very small (e.g. 10). As is explained here, these derivative-based MEs (dME) have a number of shortcomings:
Number 1: The formula above computes an estimate for the partial derivative, i.e., the tangent of the prediction function at point . The default way to interpret this is to say: if increases by one unit, the predicted target variable can be expected to increase by . Unconsciously, we use a unit change ( = 1) to interpret the computed ME even though we computed an instantaneous rate of change. For non-linear prediction functions, this can lead to substantial misinterpretations. The image below illustrates this:
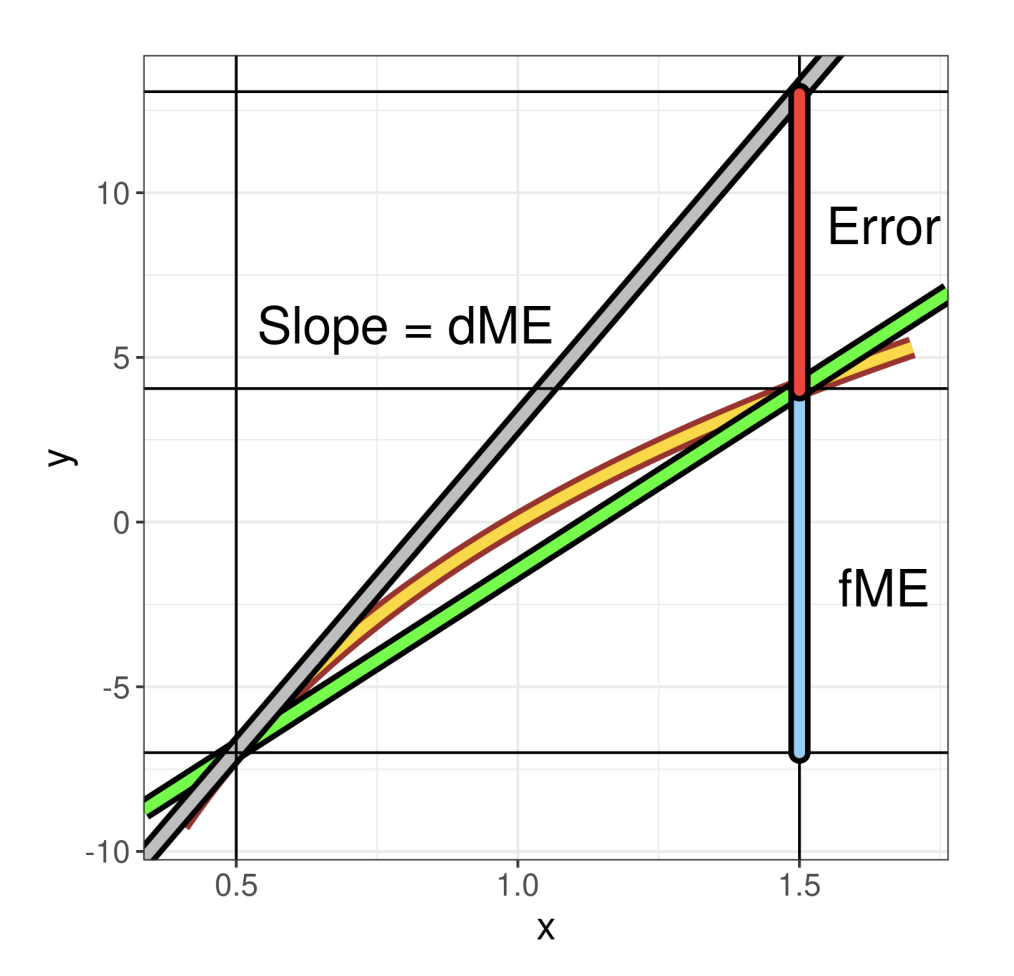
The yellow line is the prediction function, the grey line is the
tangent at point
= 0.5. If interpreted with a unit change, the dME is subject to an
error, due to the non-linearity of the prediction function. The FME,
however, corresponds to the true change in prediction along the secant
(green line) between
= 0.5 and
= 1.5. This is simply by way of design of the FME, as it describes
exactly our intuition of interpreting partial derivatives.
Number 2: In general, dMEs are ill-suited to describe models based on piecewise constant prediction functions (e.g., CART, random forests or gradient-boosted trees), as most observations are located on piecewise constant parts of the prediction function where the derivative equals zero. In contrast, FMEs allow for the choice of a sensible step size that is large enough to traverse a jump discontinuity, as can be seen in the example below: At = -2.5 (green), the dME is zero. Using the FME with = 1, we get the red point with a different (lower) function value. Here, the FME is negative, corresponding to what happens when = -2.5 increases by one unit.
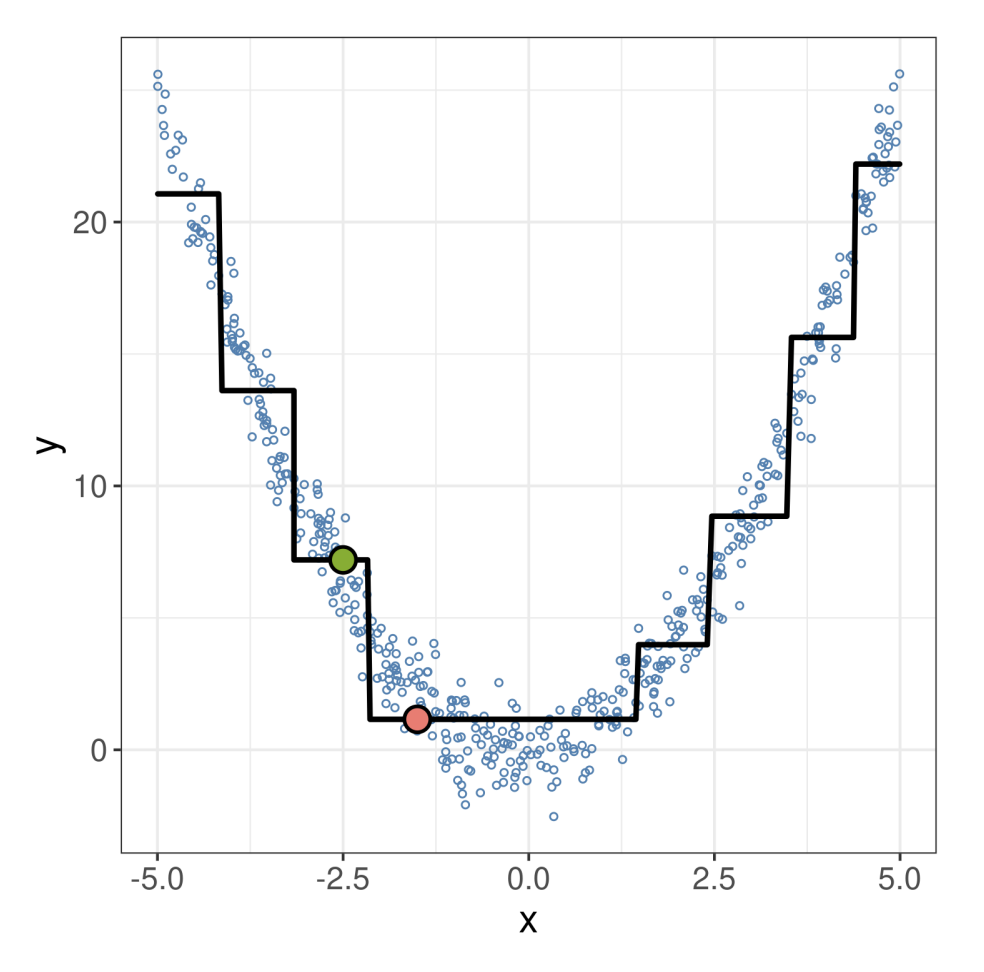
In a way, the FME is the much smarter, little brother of the
dME:
- it describes the exact behavior of the prediction function
- its design corresponds to the way we naturally want to interpret a partial derivative
- through the flexible choice of , it can be tailored to answer the desired research question
- it is conceptually simple: researchers can discuss the interpretations because they understand how they are computed